CNN là một trong những thuật toán DL cho kết quả tốt nhất hiện nay trong hầu hết các bài toán về thị giác máy như phân lớp, nhận dạng, … Về cơ bản CNN là một kiểu mạng ANN truyền thẳng, trong đó kiến trúc chính gồm nhiều thành phần được ghép nối với nhau theo cấu trúc nhiều tầng đó là : Convolution, Pooling, ReLU và Fully connected
- Các thành phần cơ bản của mạng CNN
Trước khi đi vào các thành phần cơ bản của CNN, ta xem xét một ví dụ về cách thức xử lý thông tin đầu vào của một ANN truyền thẳng để từ đó rút ra tác dụng của các thành phần có trong mạng CNN.
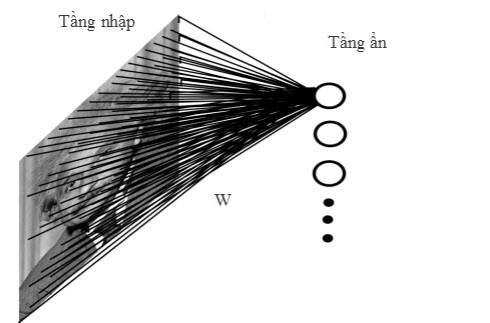
Hình 1: ví dụ mạn cách thức xử lý ANN với cấu trúc full connected
Hình 1 mô tả một ví dụ với dữ liệu đầu vào là một bức ảnh có kích thước 200 *200 được xử lý bằng ANN với kết nối đầy đủ giữa hai tầng liên tiếp (full connected). Như vậy giả sử số neural tầng ẩn là 40000 thì tổng số tham số (mà cụ thể hơn ở đây là các trọng số liên kết W giữa các neural tầng nhập với tầng ẩn) cần phải ước lượng lên đến 1.6 tỉ. Điều này gây khó khăn cho việc huấn luyện ANN trên hai yếu tố:(1) chi phí để xây dựng dữ liệu huấn luyện lớn và (2) thời gian huấn luyện lâu.
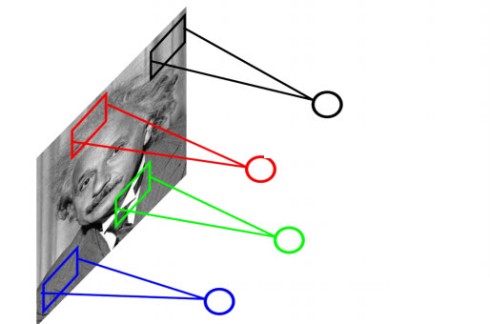
Hình 2: Ý tưởng CNN
Từ thực tế đặt ra ở trên người ta thấy rằng để giảm số lượng tham số cần giảm số lượng kết nối giữa các lớp. Từ đây thành phần convolution được áp dụng – ý tưởng chính là mỗi neural chỉ cần kết nối tới một vùng cục bộ của ảnh thay vì trên toàn bộ ảnh.
1.1 Tầng Convolution
Tầng Convolution (Conv) là tầng quan trọng nhất trong cấu trúc của CNN. Conv dựa trên lý thuyết xử lý tín hiệu số, việc lấy tích chập sẽ giúp trích xuất được những thông tin quan trọng từ dữ liệu. Hình 3 mô tả lý thuyết và cách thức Conv hoạt động trên một dữ liệu đầu vào được biểu diễn bằng một ma trận hai chiều. Ta có thể hình dung phép tính này được thực hiện bằng cách dịch chuyển một cửa sổ mà ta gọi là kernel trên ma trận đầu vào, trong đó kết quả mỗi lần dịch chuyển được tính bằng tổng tích chập (tích của các giá trị giữa 2 ma trận tại vị trí tương ứng), trong hình là giá trị đầu ra khi dịch chuyển kenel kích thước 2*2 trên toàn bộ ma trận kích thước 3*4.
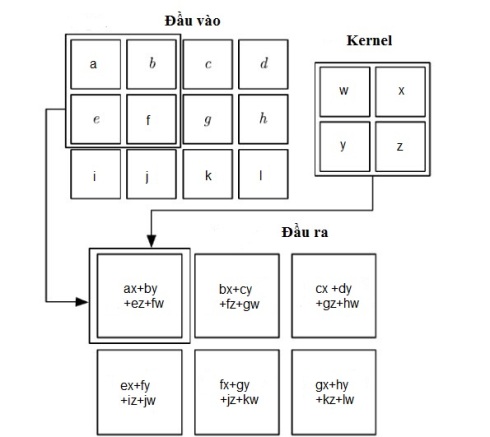
Hình 3: Ví dụ phép toán tích chập
Khi được áp dụng phép tính Conv vào xử lý ảnh người ta thấy rằng Conv sẽ giúp biến đổi các thông tin đầu vào thành các yếu tố đặc trưng( nó tương ứng như bộ phát hiện – detector các đặc trưng về cạnh, hướng, đốm màu …). Hình 4 là minh họa việc áp dụng phép tính Conv trên ảnh trong đó (a) là kết quả biến đổi hình ảnh khi thực hiện phép Conv khác nhau cho ra kết quả khác nhau, (b) là trực quan hóa các kernel dùng để detector các đặc trưng về cạnh, hướng, đốm màu
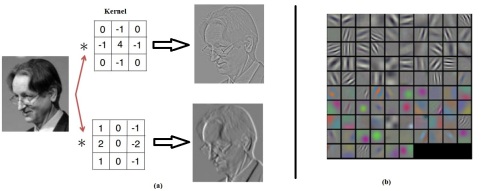
Hình 4: Ví dụ apply Conv
Để dễ hình dung, ta xét bài toán thực hiện tính giá trị đầu ra của một ảnh có kích thước $ W_1*H_1 * D_1( ở đây D_1 được gọi là chiều xâu của ảnh thực chất là giá trị tại 3 kênh màu tương ứng với ảnh RGB). Khi đó một Conv như một cửa sổ trượt (sliding window, có tên gọi là kernel, filter hay feature detector ) – cửa sổ này thực chất cũng là một ma trận có kích thước F*F thực hiện trên mỗi chiều của ảnh đầu vào (ta sử dụng K filter). Trong quá trình xử lý sẽ dịch chuyển các filter trên toàn bộ bức ảnh theo S(stride) bước (tính bằng pixcell). Người ta gọi mỗi vùng mà filter áp đặt lên ma trận đầu vào là receptive field. Trong một số trường hợp để cân bằng giữa số bước dịch chuyển và kích thước của ảnh người ta có thể chèn thêm P pixel với một giá trị màu cho trước (thường là 0) xung quanh viền của ảnh khi đó ta được ma trận đầu ra (feature map) là W_2* H_2 * D_2 trong đó:
- W_2=(W_1 – F+2P)/S+1
- H_2=( H_1 – F+2P)/S+1
- D_{2}$=K
Giá trị tại các ô trong ma trận của filter có kích thước (F*F* $ D_1) +1 (cộng 1 ở đây là tham số ngưỡng của filter) sẽ tương ứng là trọng số, các giá trị này của mỗi filter không đổi trong quá trình dịch chuyển trên toàn bộ bức ảnh đầu vào. Đây cũng là tính chất quan trọng (dùng chung bộ trọng số – shared weights) làm giảm thêm số tham số cần học trong quá trình huấn luyện mạng. Từ đó tổng số tham số cần học cho quá trình sử dụng Conv là (F*F*$ D_1)*K +K (ở đây cộng thêm k tham số ngưỡng của k filter).
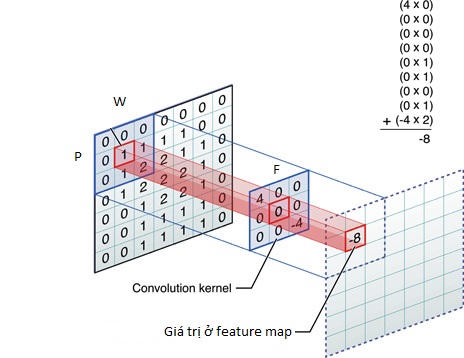
Hình 5: Các thành phần của conv
Trong hình 6 là ví dụ cụ thể, trong đó đầu vào là ảnh có kích thước (32*32*3) ở đây W_1 = H_1=32 và D_1 =3 là chỉ giá trị của kênh màu RGB. Giả sử ta tiến hành sử dụng 6 filter (K=6) trong đó mỗi filter có kích thước (5*5*3) F=3 với bước dịch chuyển S=1 v P=0. Tương ứng với mỗi filter sẽ cho một feature map khác nhau ở kết quả đầu ra trong đó: kích thước feature map là W_2 = H_2 = ( W_1 – F)/2 +1 =28. Mỗi neural trong một feature map sẽ có số tham số là (F*F* D_1) = 5*5*3 +1. Nếu không sử dụng tính chất shared weights thì số tham số cần học trong tất cả feature map trong cả 6 filter là: (28*28*6) * (5*5*3 +1) mặc dù đã nhỏ hơn nhiều so với việc không sử dụng Conv nhưng con số vẫn lớn hơn so với (F*F* D_1).K + K = 5*5*3*6+6 tham số khi dùng chung bộ trọng số.
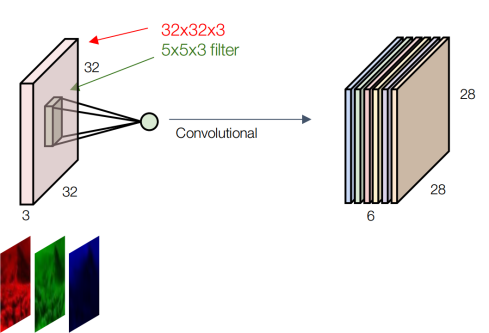
Hình 6: Ví dụ tầng Conv tron ảnh
Như vậy sử dụng Conv có những ưu điểm sau:
- Giảm số lượng tham số: Ở ANNs truyền thống, các neural ở lớp trước sẽ kết nối tới tất cả các neural ở lớp sau (full connected) gây nên tình trạng quá nhiều tham số cần học. Đây là nguyên nhân chính gây nên tình trạng overfiting cũng như làm tăng thời gian huấn luyện. Với việc sử dụng Conv trong đó cho phép chia sẻ trọng số liên kết (shared weights), cũng như thay vì sử dụng full connected sẽ sử dụng local receptive fields giúp giảm tham số.
- Các tham số trong quá trình sử dụng Conv hay giá trị của các filter – kernel sẽ được học trong quá trình huấn luyện. Như giới thiệu ở phần trên các thông tin này biểu thị thông tin giúp rút trích ra được các đặc trưng như góc, cạnh, đóm màu trong ảnh … như vậy việc sử dụng Conv sẽ giúp xây dựng mô hình tự học ra đặc trưng.
1.2 Pooling
Tầng pooling (hay còn gọi subsampling hoặc downsample) là một trong những thành phần tính toán chính trong cấu trúc CNN. Xét về mặt toán học pooling thực chất là quá trình tính toán trên ma trận trong đó mục tiêu sau khi tính toán là giảm kích thước ma trận nhưng vẫn làm nổi bật lên được đặc trưng có trong ma trận đầu vào. Trong CNN toán tử pooling được thực hiện độc lập trên mỗi kênh màu của ma trận ảnh đầu vào.
Có nhiều toán tử pooling như Sum-Pooling, Max-Pooling, L_2-Pooling nhưng Max-Pooling thường được sử dụng. Về mặt ý nghĩa thì Max-Pooling xác định vị trí cho tín hiệu mạnh nhất khi áp dụng một loại filter. Điều này cũng tương tự như là một bộ lọc phát hiện ví trị đối tượng bằng filter trong bài toán phát hiện đối tượng trong ảnh.
Về mặt lý thuyết với ma trận đầu vào có kích thước $ W_{1}$’*$ H_{1}$’ * $ D_{1}’$ và thực hiện toán tử pooling trên ma trận con của ma trận đầu vào có kích thước F’*F’ với bước nhảy S’ pixcel thì ta được ma trận đầu ra $ W_{2}$’*$ H_{2}$’ * $ D_{2}$’ trong đó:
- W_2=( W_1′ – F’)/S’+1
- H_2’=(H_1′ – F’)/S’+1
- D_2’=D_1′
Hình 7 là ví dụ về sử dụng toán tử pooling. Trong đó hình 7 (a) là cách thức tầng pooling xử lý đối với một đầu vào là kết quả của nhiều filter (k=64), kích thước của đầu vào là [224*224*64] được thực hiện với các thông số F=2 và S= 2 thì đầu ra có kích thước [112*112*64]. Hình7 (b) mô tả chi tiết cách thức hoạt động của max-pooling trong đó F=2 và S=2 kết quả đầu ra ma trận tương ứng.
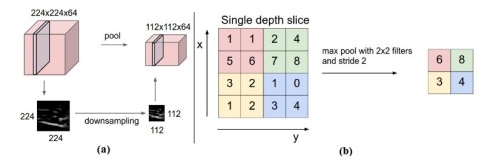
Hình 7: Ví dụ tần Pooling
1.3 ReLU
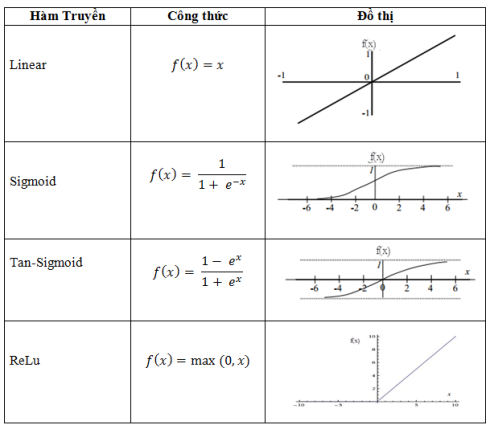
Về cơ bản, covolution là một phép biển đổi tuyến tính. Nếu tất cả các neural được tổng hợp bởi các phép biến đổi tuyến tính thì một mạng neural đều có thể đưa về dưới dạng một hàm tuyến tính. Khi đó mạng ANN sẽ đưa các bài toán về logistic regression. Do đó tại mỗi neural cần có một hàm truyền dưới dạng phi tuyến. Có nhiều dạng hàm phi tuyến được sử dụng trong quá trình này như đã giới thiệu trong phần neural căn bản. Tuy nhiên, các nghiên cứu gần đây chứng minh được việc sử dụng hàm ReLu (Rectified Linear Unit) cho kết quả tốt hơn ở các khía cạnh:
- Tính toán đơn giản
- Tạo ra tính thưa (sparsity) ở các neural ẩn. Ví dụ như sau bước khởi tạo ngẫu nhiên các trọng số, khoảng 50\% các neural ẩn được kích hoạt (có giá trị lớn hơn 0).
- Quá trình huấn luyện nhanh hơn ngay cả khi không phải trải qua bước tiền huấn luyện.
Như vậy tầng ReLu cơ bản chỉ đơn giản là áp dụng hàm truyền ReLu.
1.4 Fully-connected
Fully-connected là cách kết nối các neural ở hai tầng với nhau trong đó tầng sau kết nối đẩy đủ với các neural ở tầng trước nó. Đây cũng là dạng kết nối thường thấy ở ANN, trong CNN tầng này thường được sử dụng ở các tầng phí cuối của kiến trúc mạng.
2. Kiến trúc mạng CNN
CNN có kiến trúc được hình thành từ các thành phần cơ bản bao gồm Convolution (CONV), Pooling (POOL), ReLU, Fully-connected (FC) về mặt xây dựng kiến trúc tổng quát CNN được mô tả như sau (dấu mũi tên thể hiện thứ tự sắp xếp các tầng từ trước đến sau).
[[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC
Trong đó:
- [CONV -> RELU]*N tức là trong kiến trúc này sau tầng CONV là tầng RELU, trong CNN kiến trúc 2 tầng này có thể lặp N lần.
- POOL? là tầng Pooling cho người thiết kế quyết định có thể có hoặc không.
- [[CONV -> RELU]*N -> POOL?]*M trong kiến trúc CNN có thể lặp lại M lần kiểu sau tầng CONV là tầng RELU và kế tới là tầng Pooling.
- [FC -> RELU]*K trong CNN có thể lặp K lần cấu trúc kiểu sau tầng FC là tầng RELU nhưng trước nó phải có tầng [CONV -> RELU].
Tổng quan lại CNN là thuật toán có kiến trúc bao gồm nhiều tầng có chức năng khác nhau trong đó tầng chính hoạt động thông qua cơ chế Conv . Trong suốt quá trình huấn luyện, CNN sẽ tự động học được các thông số cho các filter – tương ứng là các đặc trưng theo từng cấp độ khác nhau. Ví dụ trong bài toán phân lớp ảnh , CNN sẽ cố gắng tìm ra các thông số tối ưu cho các filter tương ứng theo thứ tự pixel > edges > shapes > facial > high-level features. Đây chính là lý do mà CNN có được kết quả quả vượt trội so với các thuật toán trước đây.
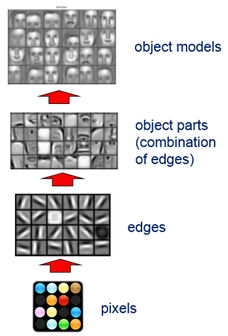
Hình 9: Ý tưởng DL
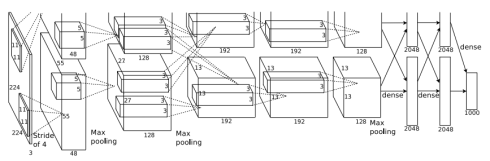
Hình 10: Kiến trúc Alexnet
Tài liệu tham khảo:
http://cs231n.github.io/convolutional-networks/